LLM에 삼국지 도메인 지식 학습시키기
안녕하세요 jiogenes 입니다
이번시간에는 작은 LLM에 삼국지 도메인지식을 학습 시켜보도록 하겠습니다.
저는 ollama로 1B 정도 크기의 LLM(주로 Llama 3.2 1B)을 로컬에 올려서 아주 간단한 질문은 여기에다 간단히 물어보고 있는데요.
당연히 삼국지는 워낙 유명하기도 하고 위키를 비롯한 인터넷에 삼국지에 대한 문서가 많이 있기 때문에 1B 짜리 LLM도 이정도 내용은 알고 있을거라 생각했습니다.
그런데, 검색해보니 엄청난 할루시네이션과 함께 삼국지에 대한 내용을 전혀 모르는것 처럼 대답을 하더군요….

너무 어이가 없을 정도로 아예 모르는 수준이라 도메인 지식이 전혀 없는 모델에 도메인 지식을 학습하는 간단한 프로젝트를 진행해보고 싶었습니다.
이런 경우 RAG를 사용하면 되긴 합니다. 하지만 단순히 “OO가 뭐야?” 정도의 질문에 RAG를 사용해서 LLM의 생성답변을 듣는것은 검색 엔진의 계산 비용 + LLM의 긴 프롬프트 시퀀스 계산 비용으로 상당히 비효율적이라 생각합니다. (검색 엔진이 사용할 DB를 생성하는것은 더더욱 엄청난 계산비용을 자랑합니다)
특히, 기업 내부자료에 대한 질의응답이나 특정 목적을 가진 LLM의 경우 LLM이 의도한 바 대로 동작하기 위해 앞에 붙이는 매우 긴 시퀀스가 항상 계산 비용의 큰 부분을 차지합니다.
따라서, 상황에 따라 RAG가 효율적인지 학습이 효율적인지는 달라질 것입니다.
데이터 준비
데이터는 간단하게 나무위키 데이터에서 삼국지 부분을 추출해보도록 하겠습니다.
해당 데이터는 나무위키 전체 문서의 제목과 본문으로 이루어져 있습니다. 따라서 제목과 본문에 적절한 키워드가 있는 문서만 추출해 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
def remove_trailing(text: str) -> str:
"""
문자열 끝에 '(삼국지)'가 붙어 있으면 제거합니다.
예: '조조전 (삼국지)' -> '조조전'
"""
if text is None:
return text
return re.sub(r'\s*\(삼국지\)\s*$', '', text)
def preprocess_dataset():
# Load dataset
dataset = load_dataset("heegyu/namuwiki-extracted", split="train")
include_title_keywords = ['삼국지', '조조', '유비', '손권', '제갈량', '관우', '장비', '조운', '여포']
include_text_keywords = ["삼국지", "삼국지연의", "삼국지(연의)", "삼국지(정사)", "삼국지정사", "나관중", "삼국지 연의", "삼국지 정사"]
except_title_keywords = ['삼국지W', '삼국지조조전', '삼국지 조조전', '삼국지 시리즈', '기타 창작물', 'DS', '디펜스', '삼국지대전', '영걸전', '영웅 삼국지', '영웅삼국지', '시, 연 삼국지화', '아이돌전', '무징쟁패', '명장 관우', '용의 부활', '백화난무', '소녀대전', '카츠마타', '쾌도난담', '헬로우', 'PK', '모던픽션', '마행처우역거', '화평자전', '곱빼기', '불편한', '건담', '시뮬레이터', '유비트', '가족 삼국지', '요시카와', '개그', '세븐나이츠', '레이예스', '퍼즐앤드래곤', '선녀강림', '황제의 반란', '조조삼소', '레전드히어로', '삼국전투기', '진삼국무쌍', '천도의 주인', '천명', '연희 시리즈', '매직 더 개더링', '같은 꿈을 꾸다', '강철삼국지', '무장쟁패', '삼국지 도원결의', '삼국지 갤러리', '레전드히어로', '와이파이', '조조전 Cost 계산기', '삼국지톡', '여포키우기', '왕자영요', '토탈 워', '삼국지 책략전', '삼국지 조운장군전', '노래하는유비', '며느리 삼국지', '하이스쿨', '요괴', '고우영 삼국지', '양지운의 라디오 삼국지', '한권으로 읽는 소설 삼국지', '영웅조조', '배틀필드', '여포양', '장비 압수', '요코야마', '톨기스', '신조조전', '소노다', '삼국지퍼즐대전', '삼국지평화', '여자 제갈량']
except_title_keywords += ['삼국지 ' + str(i) for i in range(1, 16)]
keep_indices = []
for i, item in enumerate(dataset):
if any(keyword in item['title'] for keyword in include_title_keywords) and any(keyword in item['text'] for keyword in include_text_keywords):
if any(keyword in item['title'] for keyword in except_title_keywords):
continue
keep_indices.append(i)
filtered_dataset = dataset.select(keep_indices)
filtered_dataset = filtered_dataset.map(lambda x: {'messages': [
{'role': 'user', 'content': f"삼국지에서 {remove_trailing(x['title'])}에 대해 알려줘."},
{'role': 'assistant', 'content': f"{x['text']}"}
]}, remove_columns=['text', 'title', 'contributors', 'namespace'])
return filtered_dataset
제목이나 본문에 삼국지가 포함되는 문서가 굉장히 많이 있기 때문에 게임, 웹툰과 같은 2차 창작물에 대한 문서는 최대한 제외시킵니다. (너무 naive하게 제외한것 같습니다 😭)
그리고, map 함수를 통해 채팅 폼으로 바꿔줍니다.
이렇게 하면 약 400여개의 학습 문서가 만들어집니다.
문서 갯수가 워낙 적어 eval 데이터셋을 만들기 보다는 전부 학습을 돌려봐야겠네요.
모델 학습 준비
모델은 llama 3.2 1B Instruct 모델을 준비하였고 머신은 A5000이 2장 달린 서버를 사용하였습니다.
A5000 2장을 효율적으로 사용하기위해 huggingface의 Accelerator 와 SFT Trainer를 사용하였습니다.
Accelerator
Accelerator는 huggingface에서 분산학습을 편하게 할 수 있도록 만든 라이브러리입니다.
보통은 training loop 내부에서 accelerator 객체를 통해 parameter, optimizer, data를 전부 multi-device에 분산시키는 로직을 작성합니다.
하지만 huggingface에서 같이 제공하는 trainer는 내부 로직에 accelerator 객체를 생성하여 분산학습 관리를 해주고 있으므로 2개를 같이 사용하면 training loop를 전부 작성할 필요가 없습니다.
참고로, single gpu를 사용하시는 분들은 trainer만 사용하시면 됩니다.
사용방법은 다음과 같습니다. 먼저, accelerator를 설치하고 configuration을 세팅합니다. 저는 FSDP 방법을 사용하였습니다. FSDP 설정을 제외하면 거의 기본값으로 설정해주시면 됩니다.
pip install accelerate
accelerate config
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------In which compute environment are you running?
Please select a choice using the arrow or number keys, and selecting with enter
➔ This machine
AWS (Amazon SageMaker)
config를 설정하면 대충 다음과 같은 설정파일이 만들어집니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_forward_prefetch: false
fsdp_cpu_ram_efficient_loading: true
fsdp_offload_params: false
fsdp_sharding_strategy: FULL_SHARD
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: LlamaDecoderLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
fsdp_transformer_layer_cls_to_wrap 의 값은 학습하고자 하는 모델의 Decoder 모델 클래스의 이름을 적으시면 됩니다. 정확히 적어줘야 accelerator가 어떤 레이어를 쪼개서 분산시킬지 결정할 수 있습니다.
Trainer
trainer는 정말 간단하게 사용할 수 있습니다.
먼저, 각종 config 설정을 담당하는 객체인 SFTConfig 를 생성하고, SFTTrainer로 넘겨준 후 train() 메소드를 실행하면 됩니다.
저는 다른 값들은 default 값으로 세팅해두고 fsdp 세팅을 제가 만든 세팅으로 변경해주었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
with open('/home/jyji/.cache/huggingface/accelerate/default_config.yaml', "r") as f:
fsdp_config = yaml.safe_load(f)
# Configure trainer
training_args = SFTConfig(
output_dir="./three_kingdoms_sft",
overwrite_output_dir=True,
max_steps=2000,
per_device_train_batch_size=1,
learning_rate=5e-5,
logging_steps=10,
save_steps=100,
packing=True,
fsdp="full_shard",
fsdp_config=fsdp_config,
)
# Initialize trainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset,
processing_class=tokenizer,
)
# Start training
trainer.train(resume_from_checkpoint=True)
max_steps 혹은 num_train_epochs를 설정하면 해당 스텝까지 학습을 진행하게 되는데, 저는 max_steps를 설정하겠습니다.
save_steps를 통해 100개 스텝마다 저장하도록 하고, 배치사이즈는 1로 해야 OOM이 나지 않았습니다.
train 메소드의 resume_from_checkpoint는 모델 학습이 중단되었을 때, 마지막 체크포인트에서 다시 시작하도록 하는 인자입니다.
모델 학습
이제 모델 학습을 진행하겠습니다.
accelerator를 사용하므로 accelerator 명령어를 사용해 실행시켜줘야 합니다.
accelerate launch --num_processes=2 train.py
학습이 잘 진행되는 모습을 볼 수 있습니다
{'loss': 2.7941, 'grad_norm': 6.140944957733154, 'learning_rate': 4.7275000000000004e-05, 'entropy': 2.796875, 'num_tokens': 19303.0, 'mean_token_accuracy': 0.428412127494812, 'epoch': 0.63}
{'loss': 2.5941, 'grad_norm': 5.148039817810059, 'learning_rate': 4.7025000000000005e-05, 'entropy': 2.6671875, 'num_tokens': 39464.0, 'mean_token_accuracy': 0.4652719050645828, 'epoch': 0.69}
{'loss': 2.9375, 'grad_norm': 6.429855823516846, 'learning_rate': 4.6775000000000005e-05, 'entropy': 2.83125, 'num_tokens': 59909.0, 'mean_token_accuracy': 0.41247971951961515, 'epoch': 0.75}
{'loss': 2.7102, 'grad_norm': 5.227494716644287, 'learning_rate': 4.6525e-05, 'entropy': 2.7328125, 'num_tokens': 79908.0, 'mean_token_accuracy': 0.4395463317632675, 'epoch': 0.8}
{'loss': 2.7098, 'grad_norm': 5.048852443695068, 'learning_rate': 4.6275e-05, 'entropy': 2.7703125, 'num_tokens': 100200.0, 'mean_token_accuracy': 0.4404079794883728, 'epoch': 0.86}
{'loss': 2.9445, 'grad_norm': 4.871641159057617, 'learning_rate': 4.6025e-05, 'entropy': 2.8546875, 'num_tokens': 120186.0, 'mean_token_accuracy': 0.4107069820165634, 'epoch': 0.92}
{'loss': 2.8219, 'grad_norm': 4.781363010406494, 'learning_rate': 4.5775e-05, 'entropy': 2.828125, 'num_tokens': 139869.0, 'mean_token_accuracy': 0.4183420479297638, 'epoch': 0.98}
{'loss': 2.6914, 'grad_norm': 4.973381519317627, 'learning_rate': 4.5525e-05, 'entropy': 2.665625, 'num_tokens': 159554.0, 'mean_token_accuracy': 0.4428421318531036, 'epoch': 1.03}
{'loss': 2.1187, 'grad_norm': 5.444183826446533, 'learning_rate': 4.5275e-05, 'entropy': 2.21640625, 'num_tokens': 179542.0, 'mean_token_accuracy': 0.5382856488227844, 'epoch': 1.09}
{'loss': 2.1828, 'grad_norm': 5.5732502937316895, 'learning_rate': 4.5025000000000003e-05, 'entropy': 2.2546875, 'num_tokens': 199955.0, 'mean_token_accuracy': 0.5313101500272751, 'epoch': 1.15}
{'loss': 2.7031, 'grad_norm': 5.182538032531738, 'learning_rate': 4.4775e-05, 'entropy': 2.6671875, 'num_tokens': 219752.0, 'mean_token_accuracy': 0.4415710002183914, 'epoch': 1.21}
{'loss': 2.1699, 'grad_norm': 5.348062515258789, 'learning_rate': 4.4525e-05, 'entropy': 2.19296875, 'num_tokens': 239485.0, 'mean_token_accuracy': 0.5279223829507828, 'epoch': 1.26}
{'loss': 2.5082, 'grad_norm': 5.134331226348877, 'learning_rate': 4.4275e-05, 'entropy': 2.49453125, 'num_tokens': 259080.0, 'mean_token_accuracy': 0.4811022400856018, 'epoch': 1.32}
...
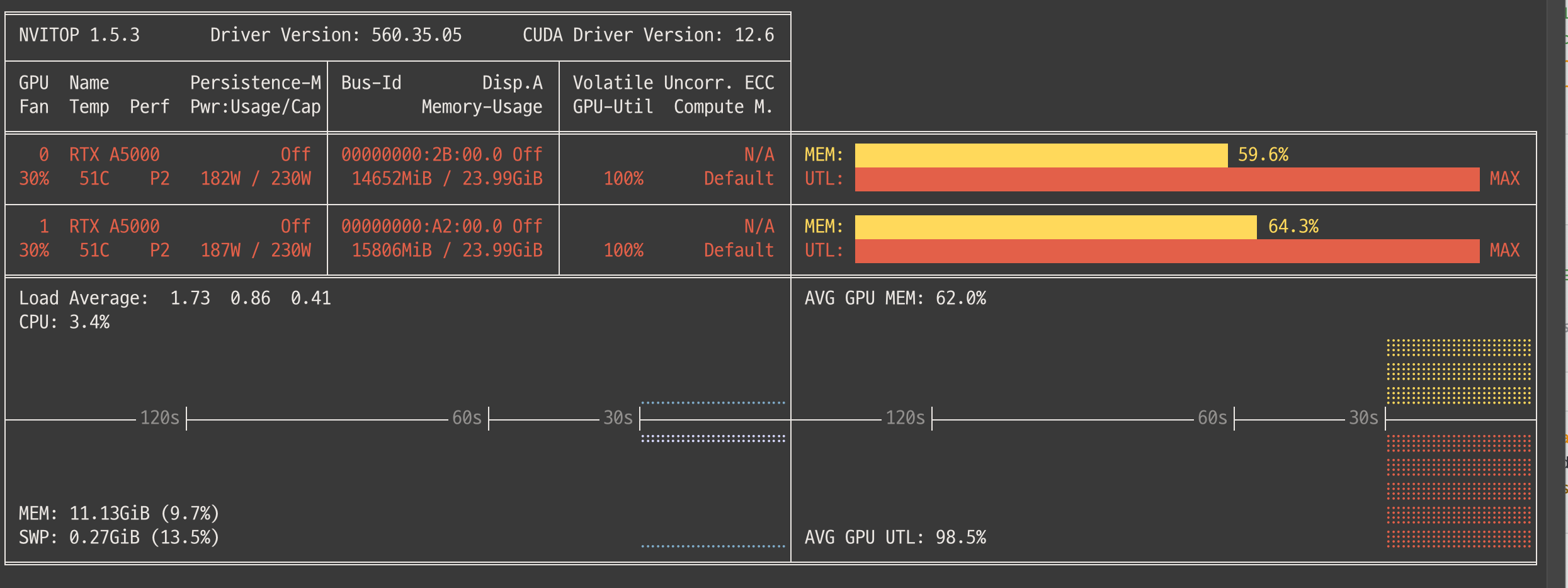
GPU 2장을 아주 잘 사용하고 있습니다.
eval dataset이 없으므로 training loss만 시각화해보겠습니다.
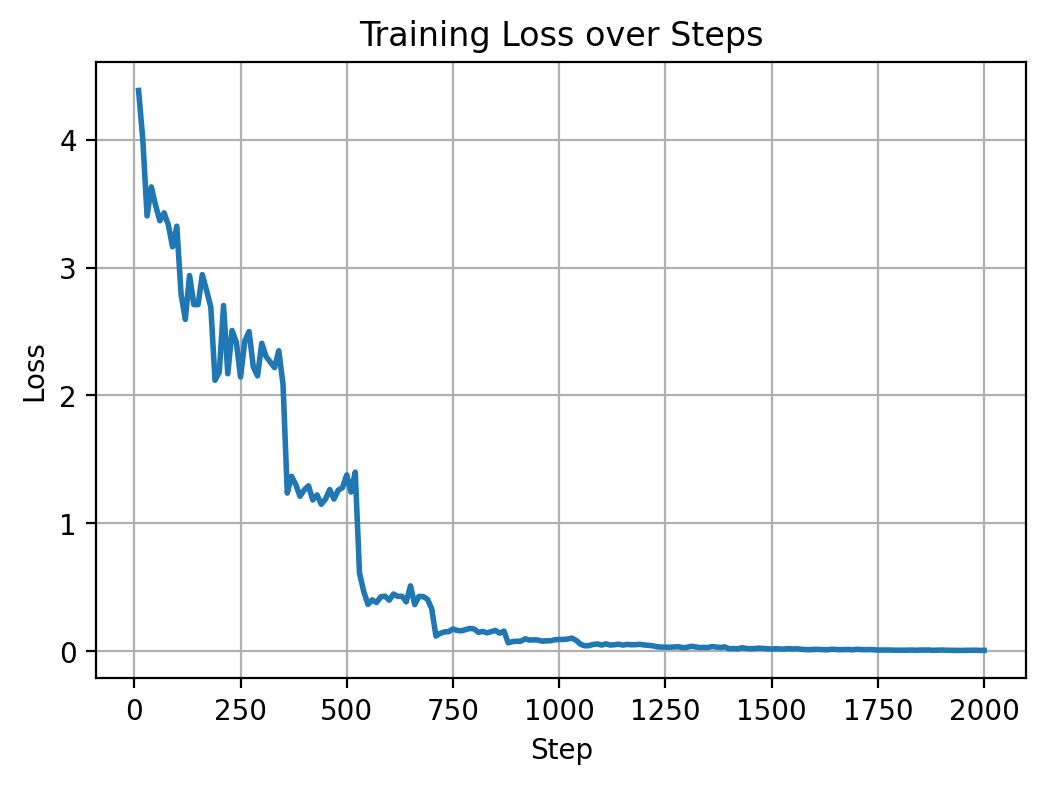
문서가 400개 정도니, 약 2에폭 이후에는 loss의 변화가 없습니다.
정성평가
정량적 평가는 삼국지 퀴즈나 이런 데이터로 해보려고 했으나 시간상 나중에 만들어 보겠습니다 😅
정성적으로 맨 앞에 보여드렸던 질문에 대해 얼마나 잘 대답하는지 여러 스텝의 checkpoint model을 불러와서 테스트해보았습니다.
질문은 똑같이 넣어줬습니다.
user
삼국지에 대해 알려줘
100스텝 때는 학습이 잘 진행되지 않아 이상한 문자의 나열이 진행됩니다.
100 step checkpoint model
assistant
삼국지연의
-1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506
500스텝 때는 질문의 내용과 다른 내용을 생성하고, 뒤 부분에는 같은 부분이 반복생성됩니다.
500 step checkpoint model
assistant
三國志
후한 말의 군벌. 자는 자원(子遠). 동평군 무양현 사람. 후한 말기의 중신인 유대와의 친척 동향이며, 유대 휘하에서 익주종사를 지낸 유선과 함께 종사를 지냈고, 유대 사후 익주의 여포가 종사를 공격해 유선이 격파당하자 유대 사후 익주성은 멸망하게 된다.
유대 사후 익주에 있던 유선과 함께 익주의 여러 군현들을 평정해 세력을 정립했다. 유대 사후 익주가 혼란스러웠기 때문에 원술의 동맹이자 호족인 유방과 조조의 공격을 받았으며, 이후 원술이 죽고 원상이 뒤를 잇자 유방과 조조가 원상을 배신해 그를 죽이고 익주를 빼앗으면서 익주의 호족들이 원상을 배신해 그 원상을 죽이고 성씨를 떨친 자들을 거병한다.
유대 사후 익주가 혼란스러웠기 때문에 원술의 동맹이자 호족인 유방과 조조의 공격을 받았으며, 이후 원술이 죽고 원상이 뒤를 잇자 유방과 조조가 원상의 배신해 그를 죽고 익주를 빼앗으면서 익주가 혼란스러웠기 때문인지 훗날 황건적의 난이 일어난 것으로 보인다.
유대 사후 익주에 있던 유선과 함께 익주를 평정해 세력을 정립했다. 이후 유대 사후 익주가 혼란스러웠기 때문에 원술의 동맹이자 호족인 유방과 조조의 공격을 받았으며, 이후 원술이 죽고 원상이 뒤를 잇자 유방과 조조가 원상의 배신해 그를 죽고 익주를 빼앗으면서 익주가 혼란스러웠기 때문인지 훗날 황건적의 난이 일어난 것으로 보인다.
유대 사후 익주에 있던 유선과 함께 익주를 평정해 세력을 정립했다. 이후 유대 사후 익주가 혼란스러웠기 때문에 원술의 동맹이자 호족인 유방과 조조의 공격을 받았으며, 이후 원술이 죽고 원상이 뒤를 잇자 유방과 조조가 원상의 배신해 그를 죽고 익주를 빼앗으면서 익주가 혼란스러웠기 때문인지 훗날 황건적의 난이 일어난 것으로 보인다.
유대 사후 익주에 있던 유선과 함께 익주를 평정해 세력을 정립했다. 이후 유대 사후 익주가 혼란스러웠기 때문에 원술의 동맹이자 호족인 유방과 조조의 공격을 받았으며, 이후 원술이 죽고 원상이 뒤를 잇자 유방과 조조가 원상의 배신해 그를 죽고 익주를 빼앗으면서 익주가 혼란스러웠기 때문인지 훗날 황건적의 난이 일어난 것으로 보인다.
유대 사후 익주에 있던 유선과 함께 익주를 평정해 세력을 정립했다. 이후 유대 사후 익주가 혼란스러웠기 때문에 원술의 동맹이자 호족인 유방과 조조의 공격을 받았으며, 이후 원술이 죽고 원상이 뒤를 잇자 유방과 조조가 원상의 배신해 그를 죽고 익주를 빼앗으면서 익주가 혼란스러웠기 때문인지 훗날 황건적의 난이 일어난 것으로 보인다.
유대 사후 익주에 있던 유선과 함께 익주를 평정해 세력을 정립했다. 이후 유대 사후 익주가 혼란스러웠기 때문에 원술의 동맹이자 호족인 유방과 조조의 공격을 받았으며, 이후 원술이 죽고 원상이 뒤를 잇자 유방과 조조가 원상의 배신해 그를 죽고 익주를 빼앗으면서 익주가 혼란스러웠기 때문인지 훗날 황건적의 난이 일어난 것으로 보인다.
유대 사후 익주에 있던 유선과 함께 익주를 평정해 세력을 정립했다. 이후 유대 사후 익주가 혼란스러웠기 때문에 원술의 동맹이자 호족인 유방과 조조의 공격을 받았으며, 이후 원술이 죽고 원상이 뒤를 잇
1000스텝 때는 나무위키의 문서와 비슷한 내용을 출력하지만, 여전히 질문의 내용과는 조금 다른 내용을 생성합니다.
1000 step checkpoint model
assistant
조위 추존 황제 太祖 武皇帝 |
寧敎我負天下人休敎天下人負我
내가 천하 사람들을 저버릴지언정, 천하 사람들이 나를 저버리게 하지는 않을 것이오.
정사에선 '천하'대신 '다른 사람'이었는데 연의에서 약간 각색된 것이다. 난세의 간웅이란 정체성을 지닌 조조를 높이 평가하는 관우의 표현과 조조의 대사, 특히 조조가 난세의 간웅이라는 사실을 감안하더라도 아무래도 그와 생김새가 같다는 것을 알 수 있다. 그 때문인지 조조와 우금의 대립사에서 우금이 조조를 비판하는 말을 종종 쓰고 있다. 예를 들어 관우의 대사에서 난세의 간웅이라는 사실을 알 수 있는 부분은
정군은 난세의 간웅이 계략을 쓰고 있으며, 기권은 난세의 간웅이 가지고 있고, 책략을 갖추고 있으며, 충성은 강력하고 세속적인 것입니다. 무릇 책략을 하고 있는 자는 명예를 갖추고, 가는 자는 사람을 알아보고, 대는 자는 나라를 구한다. 그러므로 책략을 하고 있는 자는 명예를 갖추고 가는 자는 사람을 알아보고 대는 자는 나라를 구한다.
라고 했으며, 조조가 주변에서 난세가 있는 지경에 이르러 군사들을 지휘해 싸우도록 했을 때는 주변에서 자연스럽게 교환을 할 수 있었던 것이 막연하다 못해 교환을 할 수 없었으며, 조조는 (만약 교환할 수 있었다) 그 지역의 장수들을 전부 배신하여 교주를 빼앗으면서 점령하고자 했다. 그런데 그제서야 밝혀질 게 아니라 적이 보이지 않는 것을 들었을 때
그곳은 난세의 간웅이 다 죽었어도 아직 살아남은 자가 없으니
라 하고 기권을 강력하게 하고 인재를 많이 불러 모조리 쓸 것이며, 위무와 산월의 인재들을 등용하고 상서와 군승과는 사이가 나빴으나 그 일은 그자의 깨알같은 관계였고
조조는 이 자들이 서로 불러 모조리 쓸 것을 알아보고
일단 교환을 할 수 있는 자들을 죽이고
제갈량과 사마의는 조조를 경시하여 불을 지르는 자가 벌어지게 되었다.
제갈량과 사마의는 서로 소식을 전해받고,
제갈량은 사마의의 부하가 되겠다고 조조에게 소식을 전했는데, 조조는 그 말이 옳다.
사마의는 조조의 대에 따라
그가 부하가 되지 않는 것을 원망하여
조조를 공격하겠다고 결의를 다졌으나, 오히려 조조는 사마의를 위임하길 유언했다. 참고로 사마의와 제갈량이 교전할 당시에는 사마의가 군사를 이끌고 전역을 평정하지 못했고, 유언이 당시에 주세의 위치를 알려줘 조조는 패배할 것이라며 사마의를 중용하려고 했던 것과는 크게 대립했다. 그럼에도 전략을 논의하자 사마의는 조조의 군대가 적도에서 싸우게 된 것에 대해 주장했고, 조조는 그 말을 들은. 즉 사마의와의 사이는 이 일로 더욱 멀어지게 되어 이궁의 변 때 장제가 중재해 화해를 청했다. 그리고 이에 사마의는 크게 조조의 불을 지르는 일로 법정의 바를르게 해서 사마의를 안정시켜 강하태수로 임명했다. 참고로 사마의 사후에는 전사로 목숨을 잃었을 정도로 조조가 받은 패배로 관직을 떠나 위위가 되었다. 물론 이때 조조는 위나라에 귀순했을 때 휘하에 있던 수많은 인재와의 수많은 책략을 한 번 더 확인하고는 상서와 군승을 지칭할 때 다시 언급되는 인재들이라는 걸 보면 원래 이런식으로 반드시 사마의를 죽였다는 이야기를 이야기했을지도 모른다.
이것을 기권이 장악한 조조에게 미친듯이 볼 수 있다. 장권
1500 스텝 정도부터는 나무위키의 삼국지 부분 문서를 정확하게 카피하는것으로 보입니다.
1500 step checkpoint model
assistant
중국의 2세기 말~3세기 말의 후한 말기와 삼국시대를 배경으로 한 진수의 역사서 정사 삼국지 혹은 나관중의 역사 소설 삼국지연의를 말한다. 이 둘은 이야기의 큰 줄기는 같지만 세세한 부분은 서로 다른 부분도 많다. 중국의 서기 184년 후한의 쇠퇴와 황건적의 난으로 인한 군웅할거 시대부터 사마염이 건국한 서진이 중국을 통일한 280년까지 있었던 역사를 다룬 책으로 이것의 소설판인 삼국지연의는 중국 4대 기서 중에서도 으뜸으로 치는 사람이 많으며 21세기인 현재에도 많은 사람들이 읽는 동아시아권을 대표하는 고전소설이다.
다만 삼국지를 말할 때 흔히 말하는 '정사'에는 정사 삼국지 이외에 삼국시대를 일부 다룬 후한서나 진서 등 몇몇 역사서의 내용을 포함해서 말하는 경우도 있으며, 후자의 경우는 나관중 이후 시대 삼국지연의 판본 오리지널 설정이나 화관색전 등이 포함되기도, 않기도 한다. 심지어는 20세기, 21세기에 창작된 설정이 후대 삼국지에 지속적으로 영향을 주기도 한다. 가령 도원결의 에피소드 시작 장면을 "황건적을 물리칠 의병을 구한다는 방문 앞에서 우연히 세 사람이 만났다"고 하면 기존 연의를 따른 것이고 "유비가 차(茶)를 사러 갔다 황건적 마원의를 만나 위기를 겪고 장비 덕에 목숨을 건진 뒤 장비에게 가보인 칼을 줬다가 어머니가 열 받아 차를 강물에 던져 버렸다"라고 하면 요시카와 에이지를 따른 본이다. 가장 최근의 사례로는 코에이사의 게임 삼국지 시리즈에서 시작된 수많은 설정들이 있다.
극소수는 영제의 즉위 때부터 치는 경우도 있다.
크게 진수가 쓴 정사 삼국지와 나관중의 소설 삼국지연의로 나뉜다. 정사는 말 그대로 '정확한 사실의 역사 기록'이며 연의는 소설이기 때문에 '실제 역사를 토대로 쓴 가상의 이야기'이다. 삼국지연의는 관우와 제갈량이 스타가 된 소설이기도 하며 연의 이후로 더욱 제갈량은 지혜의 화신 취급을 받고 관우는 관왕 혹은 관제라 불리며 무신(武神)이 되어 무속신앙의 대상이 되기도 한다. 여기에 다른 오호대장군도 정도는 다르지만 무속 신앙의 대상이 되었다. 근데 확실히 넘어가야 할 것은 관우가 관제묘로서 신으로 추앙받고 백성들이 유비 등을 추앙하고 제갈량 등을 지혜의 화신으로 섬긴 것은 연의보다 훨씬 이전이었다는 점이다. 추가로 많이 착각하지만 조조는 연의 이전에도 악역이었다. 서주 대학살이나, 병역을 2년에서 평생으로 늘린 둔전제 등의 영향으로 보인다. 즉, 연의 이전에도 이미 관우, 제갈량, 조조 등의 주요 인물들에 대한 평가가 이미 만들어져 있었고, 연의에서는 그러한 평가나 이미지를 극대화한 것으로 보아야 한다.
관우 신앙은 관우가 죽고 난 뒤 얼마 뒤부터 시작되어 이미 민간에선 상당한 입지를 가지고 있었다. 정확히 말하면 이미 관우의 입지가 대단하기에 삼국지연의에서 하늘로 올라가는 최후등이 추가되었다고 보는게 옳다. 물론 삼국지연의 후에 우주를 뚫을 기세가 된 것도 맞다. 한국 서울에 있는 동묘가 바로 관우를 모시는 사당이다.
이는 삼국시대가 끝나고부터 고작 몇십 년 이후의 사람인 석륵이 "장부가 일을 꾸미는 데 있어서는 마음이 호탕해서 일월과 같아야 하오. 짐은 조맹덕에 버금가는 길, '장부가 일을 꾸미는 것'이 바로 관우의 일생을 모르는 것이기 때문이다. 두보는 "장부가 일을 꾸미는
개선할 점
데이터 부족 및 평가 데이터의 부재
데이터를 수집하면서 삼국지에 대한 데이터가 생각보다 많이 없다는 느낌을 받았습니다. 기껏해야 나무위키 혹은 wiki 내부의 삼국지에 대한 문서가 전부인것 같고, 인터넷 검색 자료들은 노이즈가 너무 많아 사용하기 힘들것 같습니다. 이렇게 특정 지식에 대한 자료를 수집하는것 부터가 1차 난관이었습니다. 이렇게 데이터가 적었기 때문에 전부 학습데이터로 돌렸고, 평가 데이터는 따로 구하지 못해 평가를 할 수 없게 되었습니다. (진정한 의미에서 학습을 제대로 진행했다고 보기 어렵습니다)
전처리 한계
또한, 삼국지에 대해서 설명해놓은 문서는 있지만 문답 형태의 프롬프트로 바꾸는것도 굉장히 고된 작업이라 생각이 듭니다. 1500 스텝의 체크포인트에서 보듯이 단순히 나무위키 문서에 대한 학습은 나무위키 문서를 그대로 읊어주는 모델에 지나지 않습니다. 따라서 이 문서를 통해 좋은 문답으로 구성된 프롬프트로 만드는 것도 LLM 학습에서 성능 향상에 중요한 부분인 것 같습니다.
학습 파라미터 튜닝 및 모니터링
학습을 진행하면서 알게된점은 내가 생각한것보다 훨씬 더 많은 파라미터가 존재하고 이것이 각각 어떤 역할을 하는지 파악하기가 힘들었다는 점이었습니다. 파라미터를 이리저리 바꿔가면서 학습을 해보고 파라미터나 데이터에 따라 학습에 어떤 변화가 생기는지 모니터링 하는것도 중요하다고 생각했습니다.
제가 학습한 모델은 여기서 받을 수 있습니다.
https://huggingface.co/jiogenes/llama-3.2-1B-Instruct-three-kingdoms
그리고 학습 관련 전체 코드는 여기서 찾으실 수 있습니다.
https://github.com/jiogenes/llm-three-kingdoms-finetuning
이것으로 마치겠습니다.
읽어주셔서 감사합니다.