[논문리뷰] A Survey on In-context Learning
안녕하세요 jiogenes입니다.
오늘은 NLP에서 뜨거운 주제인 In-context learning에 대한 서베이 논문을 리뷰해보고자 합니다.
위 논문은 In-context learning(ICL)에 대한 정의와 ICL을 적용하기 위한 최신 기술들에 대한 소개 및 ICL을 활용한 application에 대해 소개하고 있습니다.
이 글에서는 제가 읽은 논문에 대해서 간략하게 소개해 놓았으며, 실제로는 더 많은 내용이 있으므로 더 자세히 알고싶은 부분은 실제 논문의 섹션에서 참고 논문을 통해 알아보시면 좋을것 같습니다.
Introduction
LLM의 규모가 커지면서 LLM은 ICL(In-Context Learning) 능력을 갖추게 되었습니다. ICL이란 문제를 해결하는 예시(demonstrations)를 모델의 프롬프트로 입력하여 새로운 문제의 정답을 예측할 수 있는 능력을 말합니다. ICL은 지도 학습과 달리 별도의 학습 과정이 필요 없고, 모델 파라미터의 그레디언트 업데이트도 요구하지 않습니다. 이처럼 놀라운 ICL 능력으로 인해 거의 모든 NLP 문제에 LLM이 사용됨은 물론, 다른 모달리티의 테스크에도 LLM을 활용하고자 하는 시도가 늘어나고 있습니다.
💡 NLP에서 프롬프트(prompt)는 주로 LLM의 입력에 들어가는 자연어 토큰들을 의미하며 demonstration(예시, 시범)은 few-shot 예제를 의미합니다.
본 논문은 ICL의 주요 이점을 다음과 같이 설명합니다:
- 해석 가능한 인터페이스 제공: Demonstration이 자연어로 구성되어 있어, 프롬프트와 템플릿을 수정하는 것만으로 LLM에 지식을 전달할 수 있습니다.
- 사람과 유사한 의사결정: 인간의 사고방식과 같은 의사결정 과정을 따릅니다.
- 학습 없는 프레임워크: 별도의 학습 없이도 적용 가능해 LLM-as-a-service가 가능하며 실세계 application에 쉽게 적용할 수 있습니다.
ICL의 많은 장점이 있지만, ICL은 여전히 연구가치가 상당합니다.
- 사전 학습(pretraining) 방식에 따라 ICL의 성능이 크게 영향을 받습니다.
- 프롬프트 템플릿, 예시 선택 및 순서(demonstration selection, order of demonstration examples)와 같은 setting에 많은 영향을 받습니다.
- 프롬프트 길이에 따른 계산 비용과 효율적인 프롬프트 설계를 위한 연구가 진행 중입니다.
- ICL의 작동 원리가 명확하지 않아 이를 해석하려는 연구가 진행 중입니다.
위 사항들을 간략하게 알아보도록 하죠.
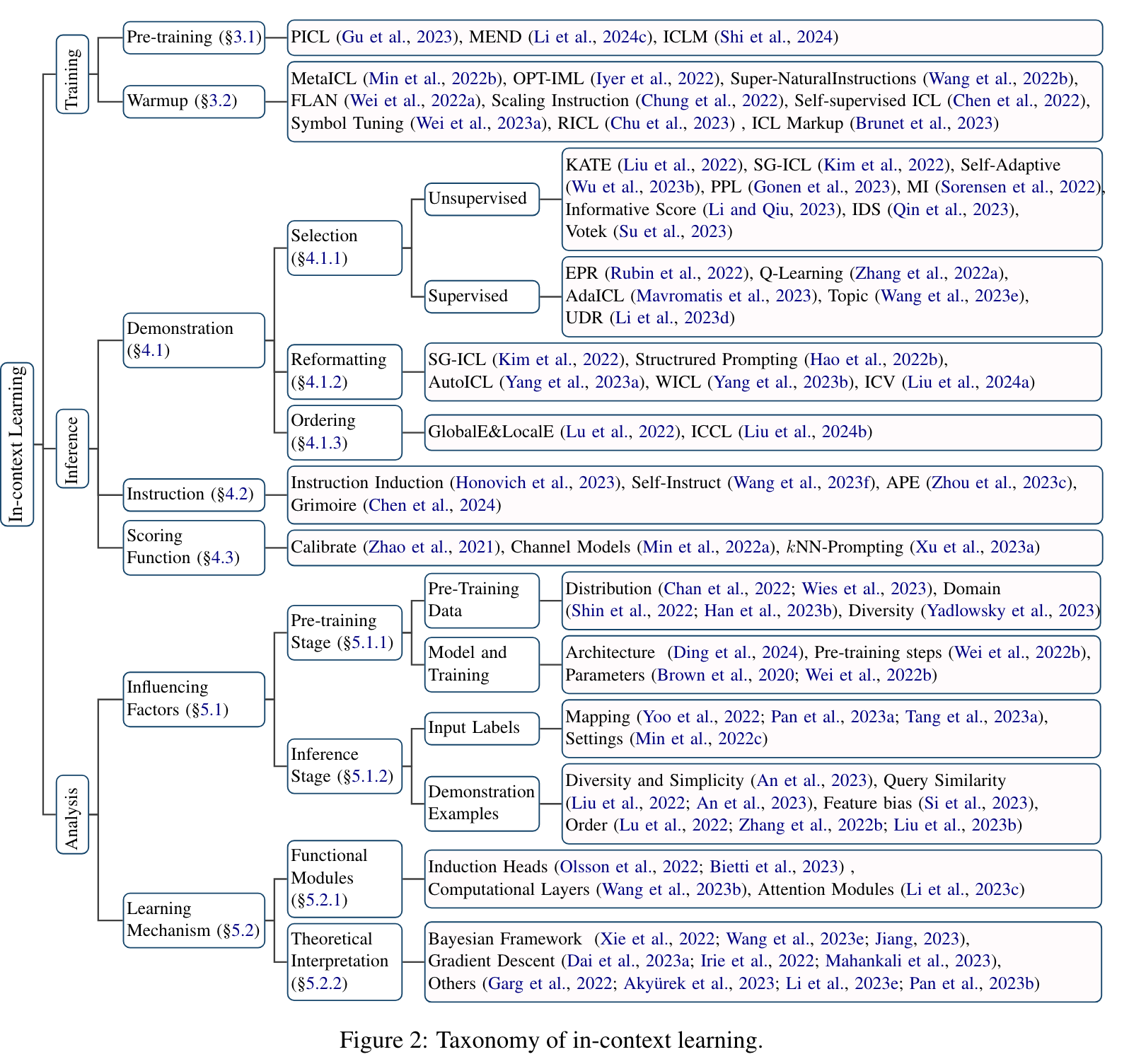
Definition and Formulation
논문에서는 인풋 텍스트 $x$ 와 answer의 후보들인 $Y={y_1, …, y_m}$이 주어졌을때 , pretrain model $\mathcal{M}$은 x와 함께 demonstration set $\mathcal{C}$의 예시들을 선택하여 가장 좋은 점수를 얻는 $y$를 선택한다고 정의합니다. 이 때, $\mathcal{C} = \{ I, s(x_1, y_1), \ldots, s(x_k, y_k) \} \quad$ or $\quad \mathcal{C} = \{ s’(x_1, y_1, I), \ldots, s’(x_k, y_k, I) \}$ 이며, 여기서 $I$는 optional task instruction(들어갈 수도 있고 안들어갈 수도 있는 테스크를 설명하기 위한 문장을 의미하는 듯 함), $k$는 demonstration 갯수 그리고 $s(\cdot)$는 템플릿을 의미합니다.
💡 $I, s$에 대한 설명이 안나와 있어 주관적 해석이 들어갔습니다.
이제, answer 후보 $y_j$의 likelihood는 스코어 펑션인 $f$로 부터 계산되어집니다:
\[P(y_j | x) \triangleq f_{\mathcal{M}}(y_j, \mathcal{C}, x)\]그리고 최종적으로 예측되는 label $\hat{y}$는 계산된 후보들 중에서 가장 높은 확률값을 가지는 후보입니다:
\[\hat{y} = \arg\max_{y_j \in Y} P(y_j | x)\]또한 논문에서는 ICL과 비교하여 prompt learning, few-shot learning과의 차이점에 대해 설명합니다. prompt learning은 prompt로 들어가는 토큰을 조작하는 모든 방법을 칭하며 이는 토큰 임베딩을 적절히 조절하거나 학습하는 방법도 포함됩니다. 따라서 논문에서는 ICL이 prompt learning의 하위 분류라고 봅니다. 또한, few-shot learning은 전통적인 machine learning에서 라벨링 데이터가 부족할 경우 사용되던 방법으로 학습이 되지 않는 ICL과 차이가 있다고 설명합니다.
Model Training
ICL 자체는 학습이 필요없지만 ICL능력을 더 강화하기 위해 pretrain model $\mathcal{M}$을 특수한 방법으로 학습시키는 방법입니다.
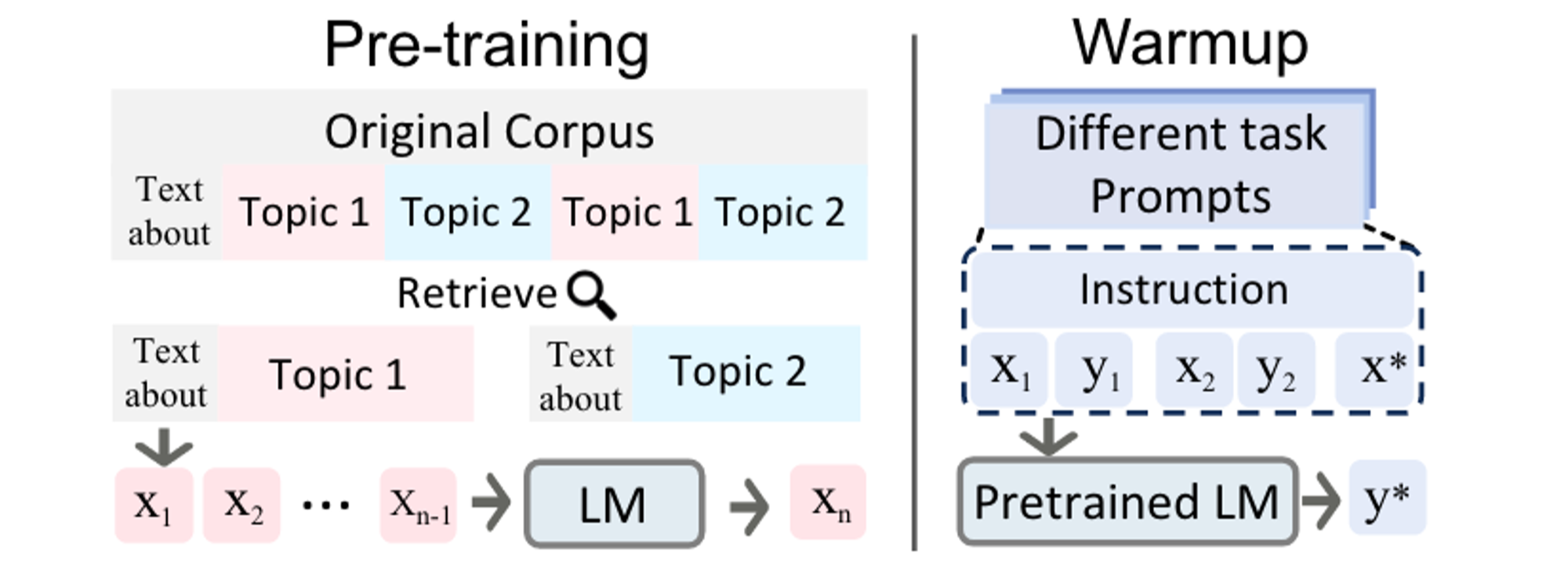
Pretraining
가장 직관적인 방법으로 ICL 성능을 높이기 위해 모델을 처음부터 직접 학습하거나 좋은 demonstration을 만들기 위한 모델을 학습하는 방법입니다.
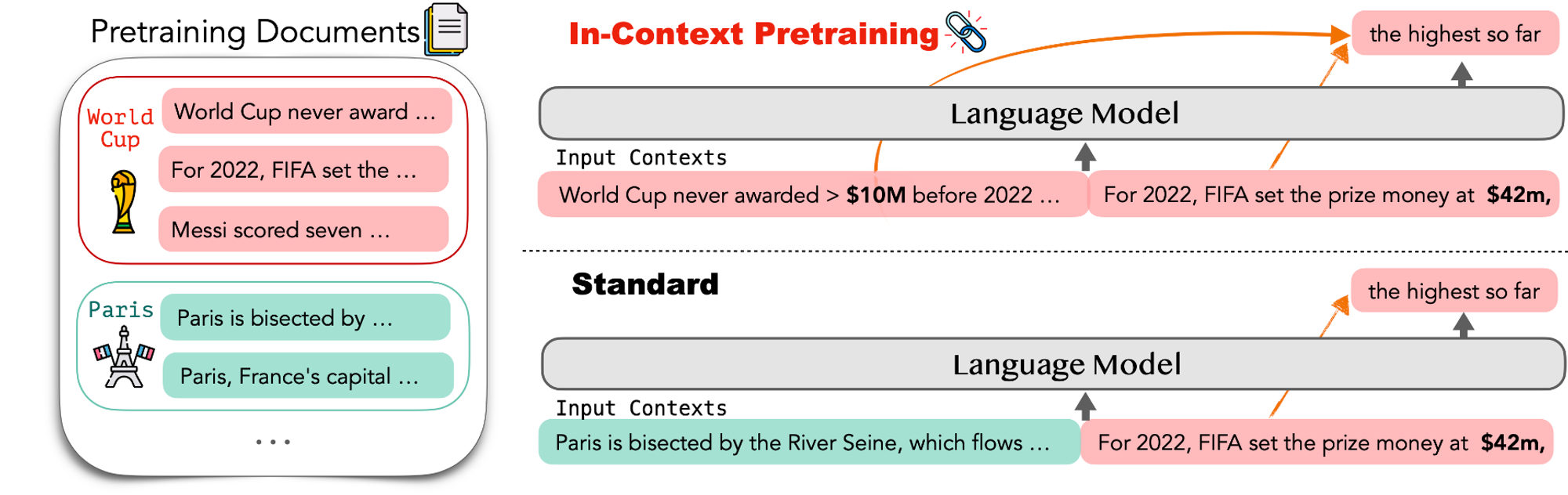
In-context pretraining 방법은 긴 context를 학습할 때 서로 연관이 없는 문서들을 이어붙여서 auto-aggressive 하게 학습하는 기존 방법을 개선하여, 서로 연관있는 문서들을 DB에서 검색해 이어붙여 긴 context를 만들고 학습하는 방법을 제안했습니다. Long context에 관한 저자들의 instight와 연관있는 문서들을 찾는 알고리즘이 눈여겨봐야할 부분입니다.
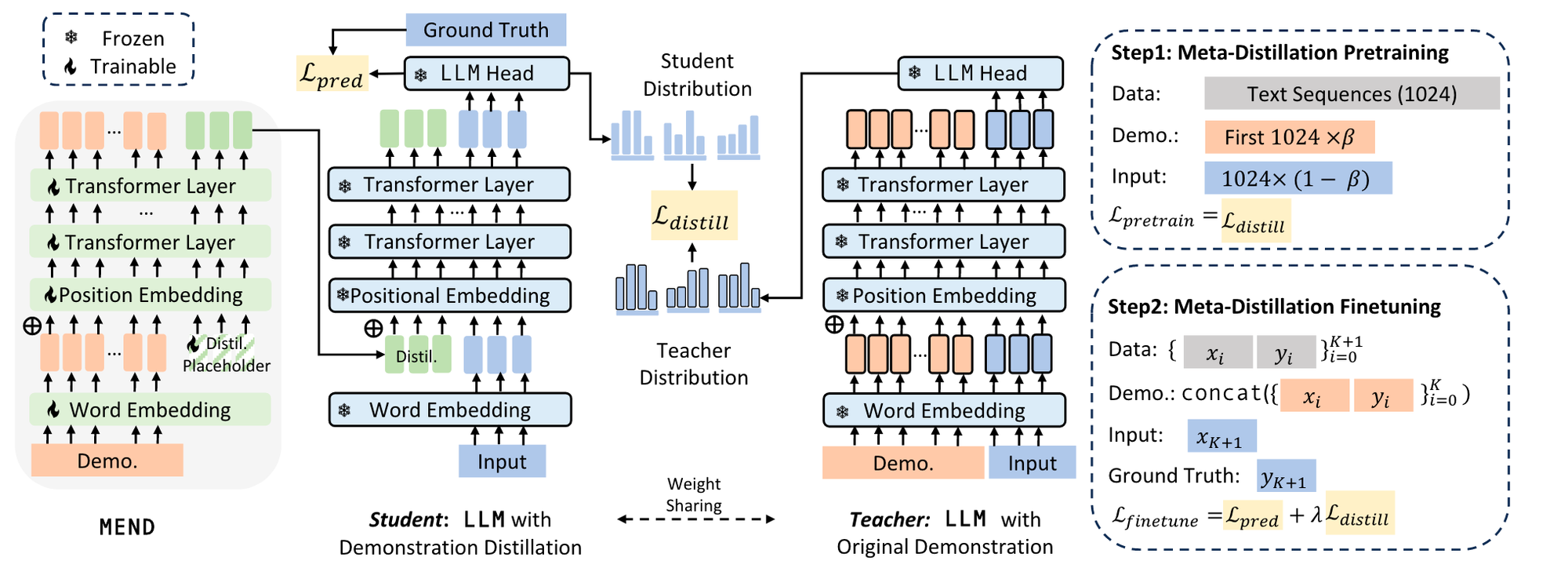
MEND는 긴 context로 인한 memory cost를 줄이면서 ICL 성능을 유지하기 위한 일종의 ICL efficiency 방법입니다. 이 방법은 2개의 LLM을 통해 demonstration의 정제(압축) 성능을 위한 loss를 계산하고, 다른 하나는 원래 성능 유지를 위한 loss를 계산하여 MEND를 학습시킵니다. 최종적으로 MEND는 긴 demonstrations를 입력받아 distilled demonstration vector를 생성하고, 이 벡터를 LLM의 임베딩 벡터 앞에 추가하여 성능 저하 없이 LLM의 context window size를 절약할 수 있습니다.
Warmup
LLM의 파라미터를 수정하거나 추가 학습을 통해 지속적으로 업데이트 할 수 있는 방법입니다. LLM을 fine-tuning하는 방법의 일종인 PEFT의 방법의 ICL 버전이라고 볼 수 있겠습니다.

MetaICL은 ICL을 통해 다양한 테스크를 풀기위한 새로운 메타학습 방법을 제안했습니다. 총 k+1개의 example을 뽑아 k개의 example을 통해 demonstration을 구성하고 남은 1개로 메타 학습을 진행함으로써 적은 수의 예제만으로 multi-task에 대한 inference 성능을 높일 수 있으며, 각 테스크의 데이터셋을 변형하지 않고 학습이 가능합니다.

또 다른 연구(Chen et al.)는 self-supervised learning을 pre-train과 downstream few-shot evaluation 사이에서 진행함으로써 ICL 성능을 향상시켰습니다. Self-supervised learning은 BERT, GPT, FLAN 등에서 사용한 여러 left-to-right language modeling 학습방법입니다.
Prompt Designing
Demonstration Organization
많은 연구들이 demonstation의 selection, formatting, ordering에 따라 ICL의 성능에 크게 영향을 준다고 합니다. 이 세 부분에 각각 세부적으로 살펴보도록 하죠.
Demonstation Selection
Demonstration selection은 ICL 성능을 위해 “어떤 샘플이 가장 좋은 예시일까?” 라는 물음에서 출발합니다. 본 논문에서는 demonstration selection 문제를 비지도 학습 방법(Unsupervised Method)과 지도 학습 방법(Supervised Method)으로 나눕니다. 위 에서 봤던것 처럼 model을 학습하는지 안하는지에 대한 것이 아니라, demonstration을 뽑는 retriever(검색기)를 비지도 학습과 지도 학습으로 구분해 설명합니다. 따라서 논문과 조금 다르게 unsupervised retriever, supervised retriever로 명명해서 설명하도록 하겠습니다.
Unsupervised retriever는 직관적으로 input instance와 가장 유사한 예시들을 선택하여 demonstration을 만드는 retriever를 뜻합니다. 얼마나 유사한지 계산하기 위해 L2 distance와 cosine similarity와 같은 distrance metric을 사용할 수 있습니다. 본 논문에서는 machine learning에서 대표적인 비지도학습 방법 kNN, 그래프와 confidence score, mutual information, perplexity 등을 사용하는 방법 등을 소개하고 있으며, LLM의 output을 비지도 학습의 평가지표로 활용하는 방법도 소개하고 있습니다. 저는 대표적인 2가지만 소개하겠습니다.
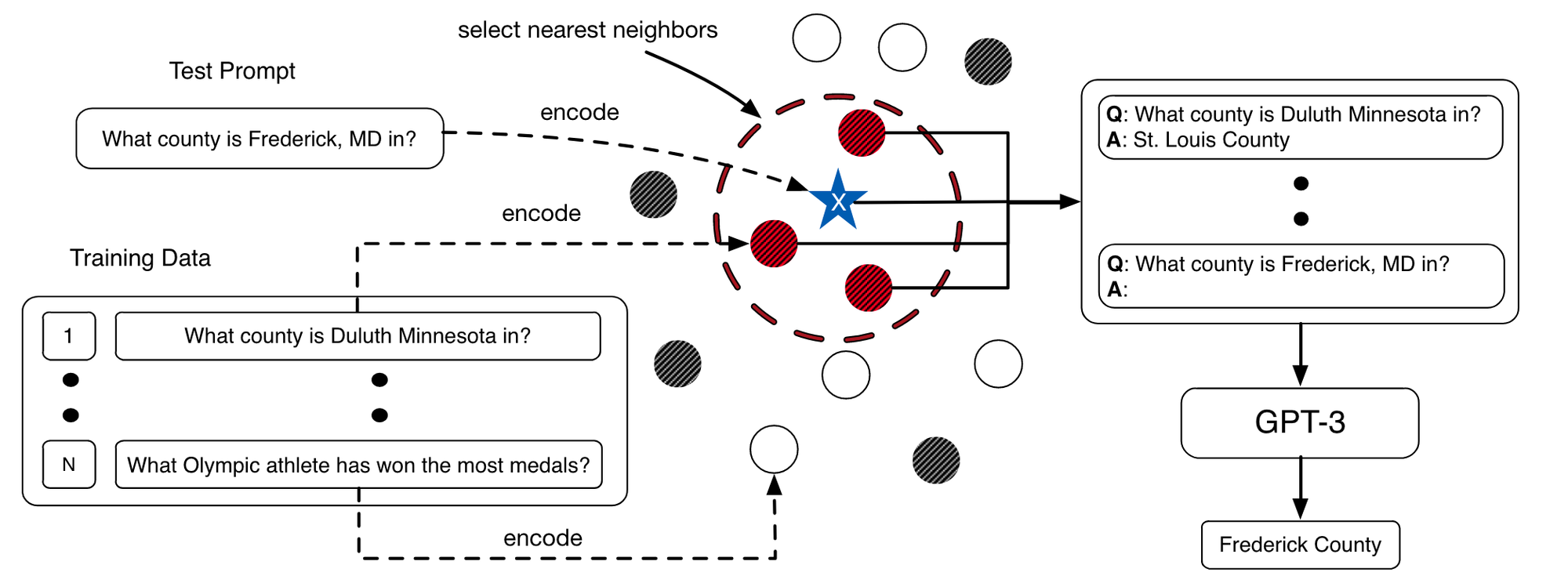
먼저, KATE은 RoBERTa와 sentence embedding modeule을 통해 query input과 어휘적, 의미적으로 비슷한 문장을 찾아 demonstration을 구성하는 example들을 selection하는 방법입니다. 이 방법은 random하게 sample을 뽑는것 보다 더 좋고 일관성 있는 결과를 보여줍니다.
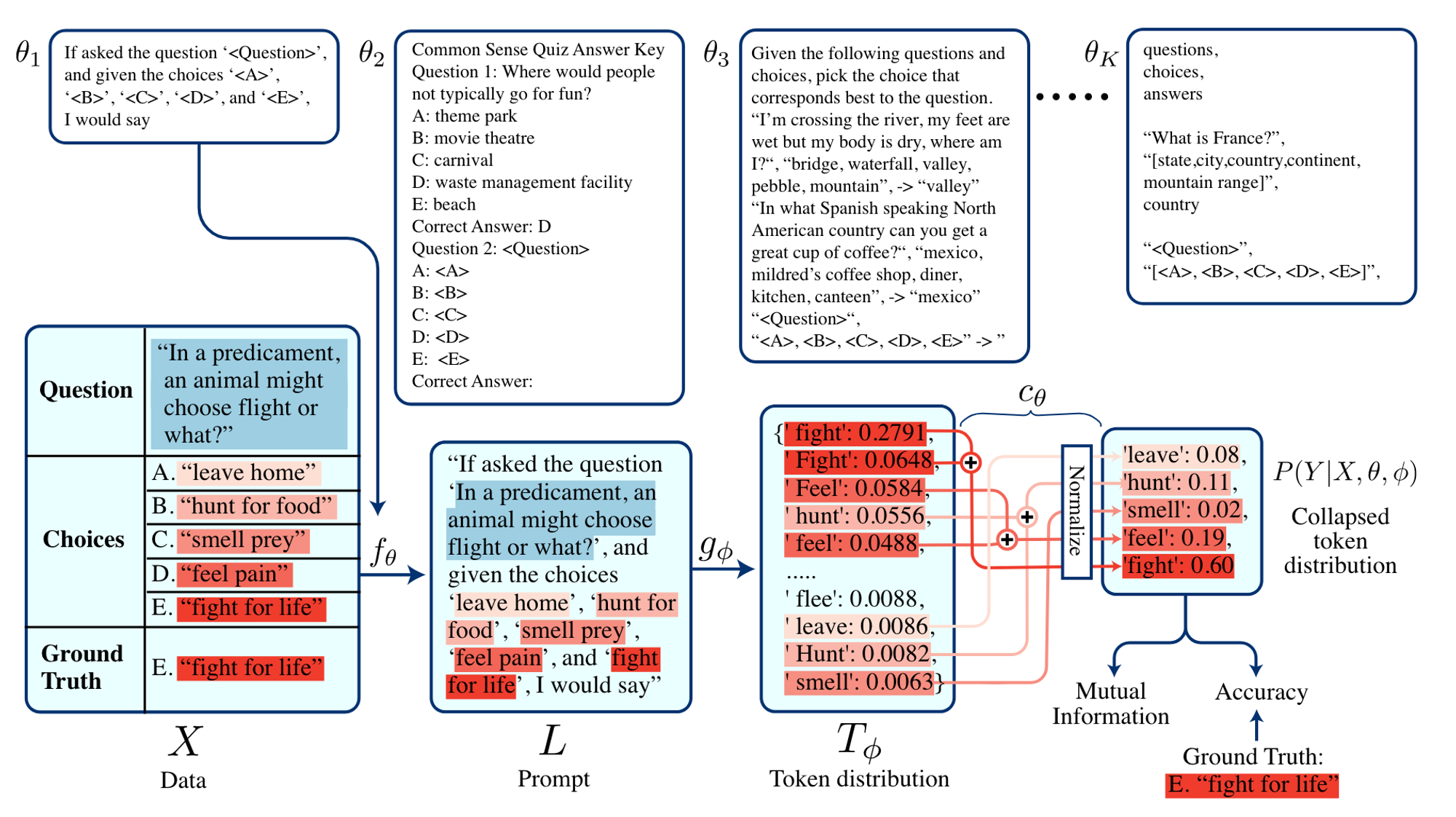
Mutual Information을 사용하는 연구는 모델파라미터 접근과 labeled examples 없이도 demonstration을 적용하는 효과적인 방법을 제시했습니다. Mutual Information $I$는 엔트로피 $H$로 다음과 같이 표현할 수 있고 $I(X;Y)=H(Y)-H(Y|X)$, 각각의 example과 template의 MI계산을 통해 여러 prompt template $\theta$ 중에서 가장 다양한 응답을 고려함과 동시에 가장 confidence가 높은 $\theta$를 고를 수 있습니다.
마지막으로 Self-Adaptive In-Context Learning 방법은 demonstration selection과 ordering을 동시에 고려하는 방법입니다. (Demonstration Ordering은 뒤에 나오지만 unsupervised retriever라는 관점에서 봐주시면 될것같습니다) Demonstration selection & ordering을 일종의 search problem으로 보고, top-K개의 example을 뽑아 search space를 줄인 뒤에 Minimum Description Length (MDL) 원리를 이용해 input prompt가 정답 y로 가장 잘 압축될 수 있는 demonstration order를 선택합니다. top-K는 KATE에서 사용된 방법을 사용합니다.
Supervised retriever는 특정 task에 휴리스틱하고 sub-optimal한 unsupervised retriever와 달리, 특정 task를 좀 더 잘 수행할 수 있도록 학습을 하는 retriever입니다.
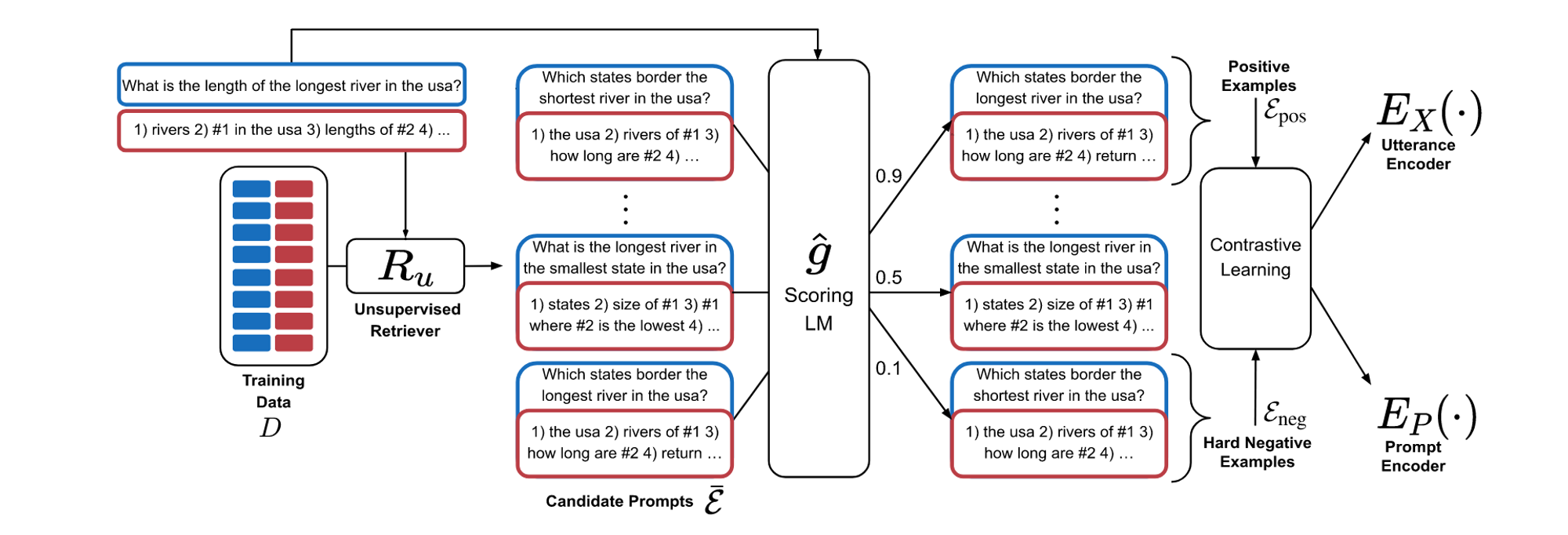
EPR은 two-stage 방식으로 학습이 진행되는데, 먼저 unsupervised method로 example들과 input을 모두 latent vector로 변환한 후 이 vector를 통해 학습을 진행합니다. 구체적으로, train example set과 test example set을 나누고 train example set만 가지고 retriever를 학습합니다. 학습을 위해 먼저 학습데이터를 모두 latent vector로 변환한 후 GPT-Neo와 같은 작은 모델로 training data의 정답 label을 통해 한 example과 다른 example 사이의 socre를 얻습니다. 이 score를 통해 top-k, bottom-k sample을 얻고, input data를 인코딩 하는 $E_X$와 demonstration을 인코딩 하는 $E_P$를 contrastive learning을 통해 학습합니다.
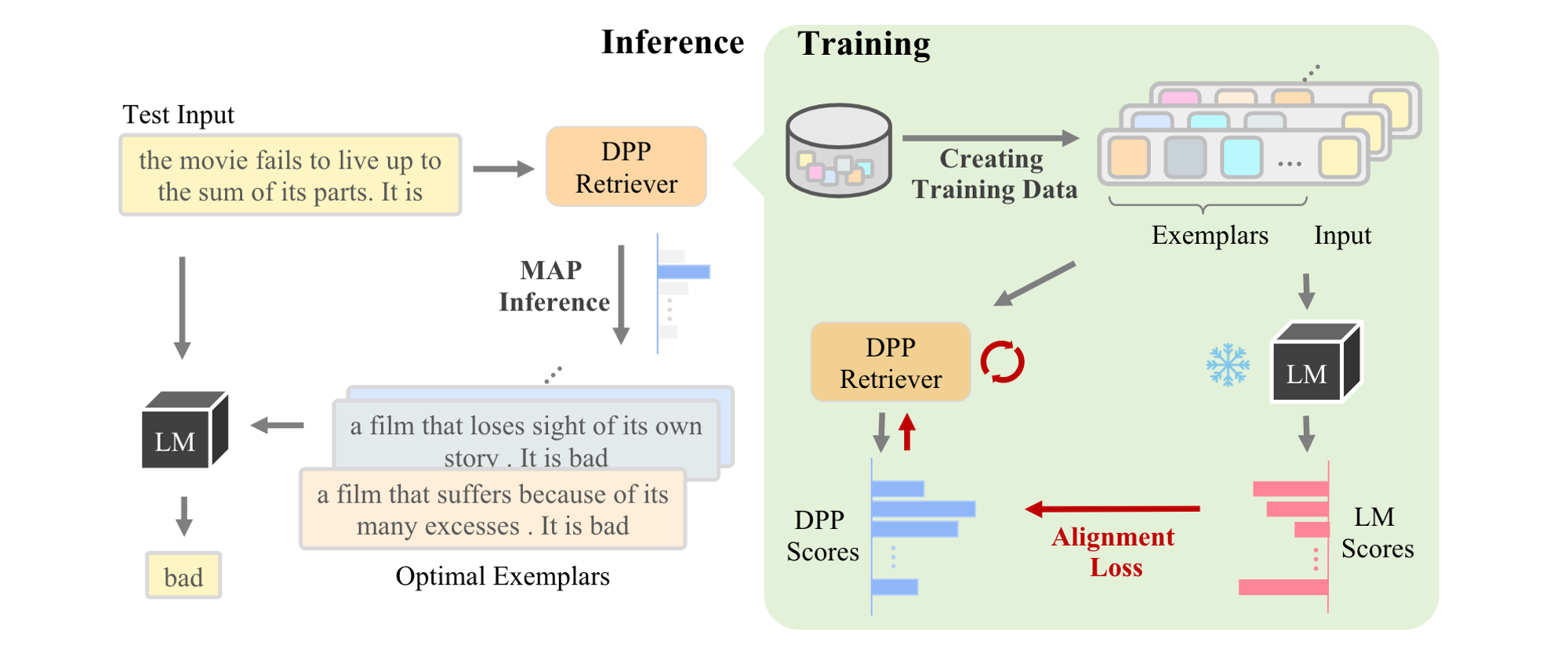
CEIL은 최적의 demonstration을 example 각각 하나씩 계산하는것이 아니라 subset selection 문제로 상정하고 한번에 계산하는 방법을 제시했습니다. DPP를 이용해 고정된 example의 집합내에서 부분집합에 대한 확률 분포를 계산하여 부분집합 자체에 대한 contrastive learning을 수행합니다. 이 논문에서는 DPP를 약간 변형하여 test set과 관련이 높으면서도 demonstration 부분집합 내부의 example끼리 다양성을 보장하는 retriever를 학습합니다.
Demonstation Reformatting
Demonstration reformatting은 LLM을 사용해서 demonstration을 재구성하거나 새로 작성하는 방법을 말합니다.
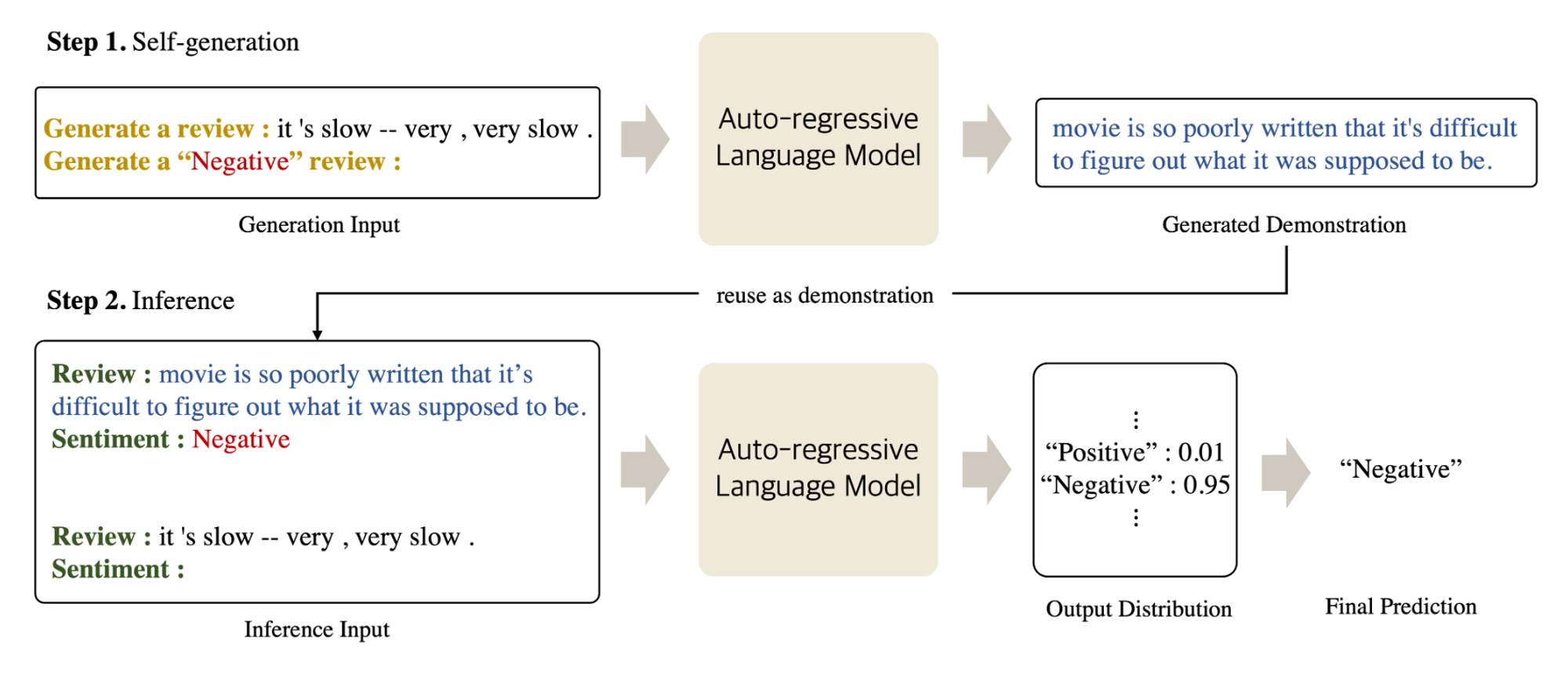
SG-ICL은 ICL의 demonstration 의존성을 제거하기 위해 LLM을 통해 새로운 demonstration을 생성한 후에 생성된 demonstration으로 inference를 수행합니다.
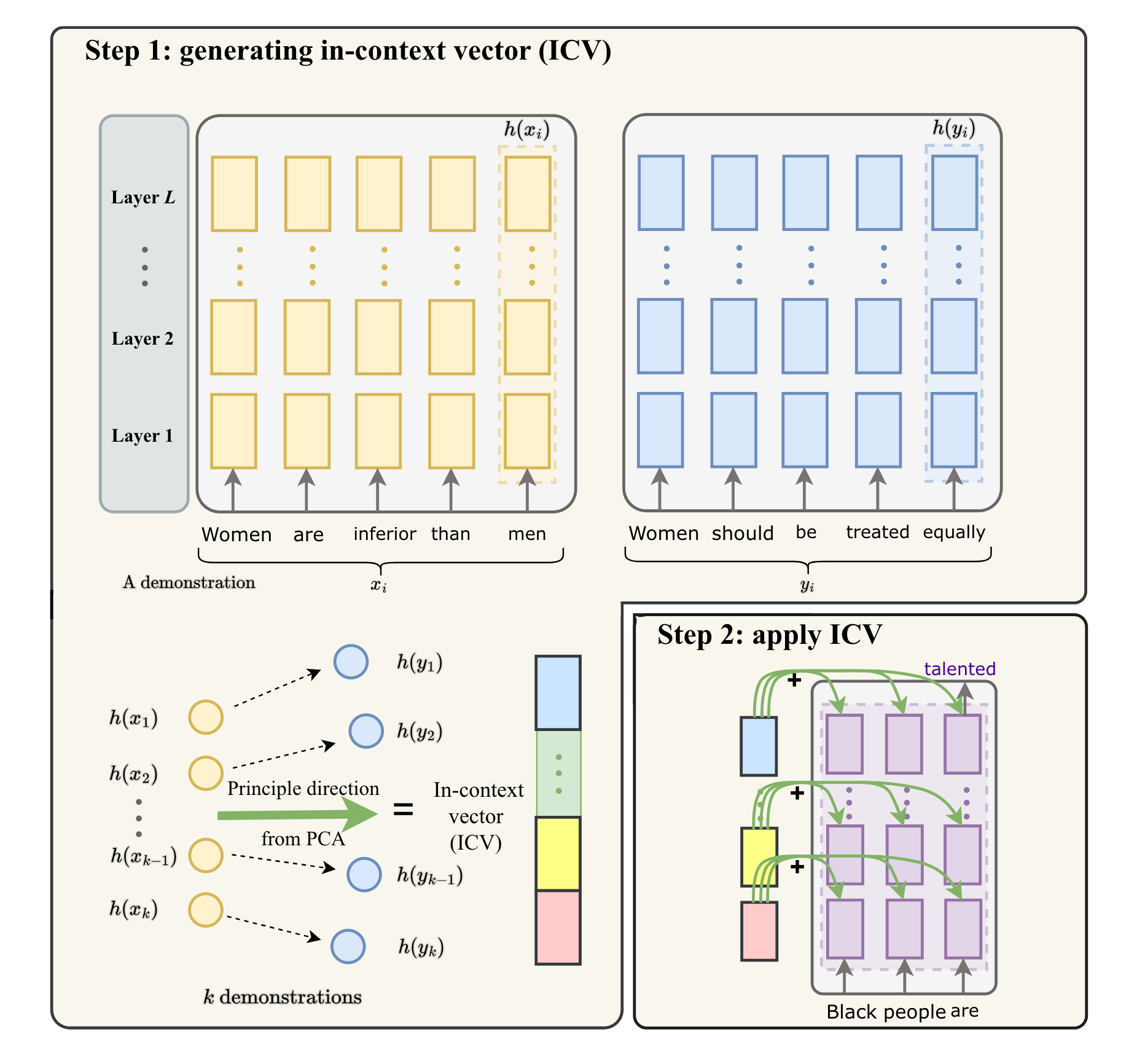
ICV(In-context vectors)는 demonstration text를 미리 LLM에 입력하여 마지막 token에 대한 latent vector(ICV)를 추출합니다. Inference시에는 ICV를 각 레이어의 latent vector에 더해줌으로써 in-context learning의 context length에 대한 제한을 극복할 수 있습니다.
Scoring Function
Scoring function은 LLM의 예측을 특정 answer의 likelihood로 평가하는 방법입니다. LLM의 출력은 token sequence로, 생성될 수 있는 답변의 수가 매우 많습니다. 하지만 많은 NLP task에서는 정확한 정답(golden label, specific class 등등)을 요구합니다. Scoring function은 생성된 토큰 시퀀스에서 정답을 추출하고, 그 답이 올바른지 아닌지를 판별하는 방법을 설명합니다.
가장 직관적으로는 LLM이 출력할 수 있는 모든 token 중에서 가장 높은 확률을 가지는 token을 선택하는 방법입니다. 이 방법은 LLM이 입력 뒤에 바로 정답을 출력하도록 해야 하므로 template를 만드는데 많은 제약이 따릅니다.
다른 방법으로는 Perplexity(PPL)을 이용하는 방법이 있습니다. PPL은 정답 token의 포지션에 구애받지 않는다는 장점이 있지만 정확한 label을 추출하는데 추가적인 계산 비용이 들어갑니다.

Channel models 방법은 text classification 문제에 한해서, input $x$ 가 주어졌을때 output $y$의 확률 계산시 $P(y|x)$로 계산하는 Direct model 방식과 달리 output $y$가 주어졌을때 input이 $x$일 확률 $P(x|y)P(y)$을 구하는 channel model을 제안합니다. 이는 정보이론의 noisy model이 등장한 동기와 비슷하게 model이 불균형한 데이터나 적은 라벨링 데이터를 가지고 있을때 보다 더 뛰어난 성능을 발휘합니다. 논문에서는 prompting 방식과 fine-tuning방식 모두 적용해서 비교를 했습니다.
Finally
이 다음 섹션부터는 ICL의 근본적인 작동원리를 파해치고자 하는 분석 논문들이 나옵니다. 하지만 저는 분석논문들 까지는 다 읽어보지 못했습니다 🥲 분석은 또 다른 중요한 분야이긴 하지만 응용과 분석은 조금 결이 달라서 저는 쭉쭉 읽기가 힘들더라고요 😭 기존의 language model들을 분석하던 분들이 ICL의 분석도 연구하시는 것 같습니다. 이쪽도 좋은 논문들이 많이 나오고 있고 ICL의 기본 원리에 대해서 다시한번 생각해보거나 참신한 방향으로 생각해볼 수도 있기 때문에 시간이 되는대로 읽고싶네요.
논문을 읽으면서 완성도가 높고 논리적으로 깔끔한 논문도 많았지만 arxiv에만 올라와있는 논문들 중에는 아직 논리나 근거가 부족하거나 글이 연결이 되지 않는경우도 있었습니다 😅 다르게 생각해보면 ICL이라는 주제가 그만큼 뜨거운 감자라는 사실은 변함이 없는것 같군요! 열심히 연구해서 저와 여러분들 모두 좋은 논문을 낼 수 있었으면 좋겠습니다. 끝까지 읽어주셔서 감사합니다! 🤗
잘못된 부분에 대한 지적은 언제나 환영입니다.
참고문헌
[1] A Survey on In-context Learning (Dong et al., arxiv 2022)
[2] In-context Pretraining: Language Modeling Beyond Document Boundaries (Shi et al., arxiv 2023)
[3] https://www.harmdevries.com/post/context-length/
[4] MEND: Meta dEmonstratioN Distillation for Efficient and Effective In-Context Learning (Li et al., ICLR 2024)
[5] MetaICL: Learning to Learn In Context (Min et al., NAACL 2022)
[6] Improving In-Context Few-Shot Learning via Self-Supervised Training (Chen et al., NAACL 2022)
[7] What Makes Good In-Context Examples for GPT-3? (Liu et al., DeeLIO 2022)
[8] An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels (Sorensen et al., ACL 2022)
[9] Learning To Retrieve Prompts for In-Context Learning (Rubin et al., NAACL 2022)
[10] Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering (Wu et al., ACL 2023)
[11] Compositional exemplars for in-context learning (Ye et al., ICML’23)
[12] Self-Generated In-Context Learning: Leveraging Auto-regressive Language Models as a Demonstration Generator (Kim et al., arxiv 2022
[13] In-context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering (Liu et al., arxiv 2023)
[14] Noisy Channel Language Model Prompting for Few-Shot Text Classification (Min et al., ACL 2022)